當然最後還是搜到了,但就希望可以多寫一篇文,讓這些解法更容易被搜到,如果運氣很好真的幫到人也算功德一件,
畫上座標線:
這算是一個附加功能,一般的顯示工具只要設定 Scene 的 background brush,設定一個黑色的 brush,就能畫出黑色背景了。但如果我們要更精細的話,就要去實作 scene 或是 view 的 drawBackground 函式:
void drawBackground(QPainter *painter, const QRectF &rect)
下面是我實作的程式碼節錄,有幾個可以注意的地方:
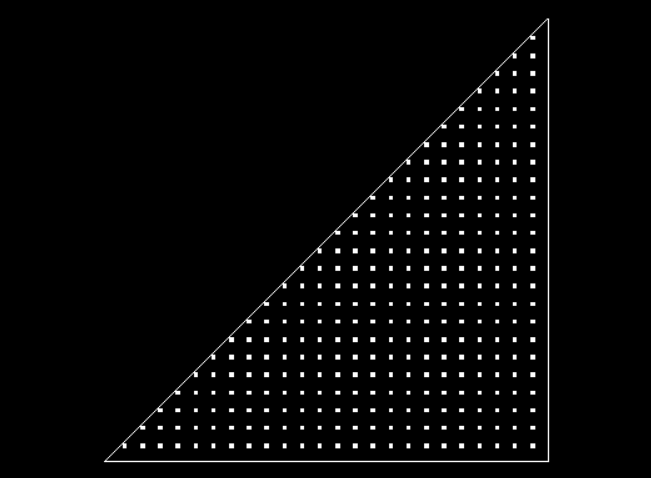
- Qt 的座標系統左上角是 0,0,往右往下是 x 遞增跟 y 遞增,所以用 top 的值會比 bottom 小。
- 這個函式參數是一個 QPainter 跟一個 QRectF,painter 好理解就是目前作畫的對象,在這個 painter 上面作畫就會畫在背景上;QRectF 一般會認為就是現在顯示背景的矩形,不過不對,它是「現在要更新背景的範圍的矩形」。
例如我現在顯示的 Scene 大小是 -50,-50 ~ 50, 50,但我實作滑鼠可以在 scene 上面拉一個選取的小框框,在我拉框框的時候,Qt 會判定只有這個小框框裡面的背景是需要重畫的,QRectF 就會設定到這個小框框上;其實某種程度來看這樣也對,而且更節省重畫的資源。 - 承上點,所以有抓到現在 scene 的大小要怎麼辦?這也是我為什麼選擇是實作 View 的 drawBackground 而不是 Scene 的,因為我可以透過 mapToScene(viewport()->rect()).boundingRect() 取得這個 View 現在顯示 Scene 的大小。
void
MyViewer::drawBackground(QPainter *painter, const QRectF &rect) {
qreal left = rect.left();
qreal right = rect.right();
qreal top = rect.top();
qreal bottom = rect.bottom();
QRectF sceneRect = mapToScene(viewport()->rect()).boundingRect();
qreal size = qMax(sceneRect.width(), sceneRect.height());
qreal step = qPow(10, qFloor(log10(size/4)));
qreal snap_l = qFloor(left / step) * step;
qreal snap_r = qFloor(right / step) * step;
qreal snap_b = qFloor(bottom / step) * step;
qreal snap_t = qFloor(top / step) * step;
// print coordinate point
for (qreal x = snap_l; x <= snap_r; x += step) {
for (qreal y = snap_t; y <= snap_b; y += step) {
painter->drawPoint(x, y);
}
}
// print coordinate line
painter->drawLine(qFloor(left), 0, qCeil(right), 0);
painter->drawLine(0, qCeil(bottom), 0, qFloor(top));
QGraphicsView::drawBackground(painter, rect);
}
不動物件:
第一個是所謂的不動物件,也就是 QGraphicsItem 透過設定了 ItemIgnoresTransformations flag,這樣這個 item 就不會受到 view 視角變化的影響。使用情境也很單純,像是在畫面上打個 marker 或是寫上文字,如果視窗縮小就看不到就奇怪了,所以這個 marker 就要設定這個 flag,放大縮小都會顯示一樣。
改變也就是呼叫一下
setFlag(QGraphicsItem::ItemIgnoresTransformations, true);就可以了。
要注意的是在設定了這個 flag 之後,在這個 item 裡面的位移似乎會失去效果(還是行為會變很怪,我有點忘了),一般要在一個位置例如 100, 100 畫一個正方形,我們可以用 QGraphicsRectItem,在 100, 100 的地方畫正方形;如果是 ignore transformation 的物件,我是變成在 0,0 的位置畫一個正方形,然後把物件的位置用 setPos 設定在 100, 100。
這部分當初真的弄超久,後來覺得這樣不行,把放在 dropbox 裡面的 <c++ GUI Programming With Qt 4> 拿出來翻翻,沒想到在第八章 Qt graphics 章節就講了要怎麼寫類似的東西,還有範例 code ,果然寫程式還是要多看書而不是瞎攪和,弄了好一陣子的東西其實書上的範例都寫了。
填充物:
上一篇文的最後一張圖,應該很明顯可以看到,我用 brush 填進去的東西,非常的…不均勻,一格一格的非常醜,實際運作的 code 也是,只要放大縮小填充物的就會變得不連續。這是因為 QBrush 在填東西的時候,用固定密度在填充,不會隨著螢幕的放大縮小改變填充物的密度,要修成也只需要一行,在 paint 函式裡面加上這個:
QBrush m_brush; m_brush.setTransform(QTransform(painter->worldTransform().inverted())); painter->setBrush(m_brush)把現在場景的變形反轉補償回去就可以了;這個解答出自 Stack Overflow。
隨放大縮小調整長度:
同樣的是另一張圖的箭頭,在放大縮小的時候,箭頭的部分會跟著放大縮小,這是我們不想要的,因為縮太小的時候箭頭會看不到,這時候就要用到我們上篇提到的 QStyleOptionGraphicsItem,在 paint 函式裡面,可以用這個東西從 painter 的 transform 裡取得 level of detail (LOD):qreal qScale = option->levelOfDetailFromTransform(painter->worldTransform()); qreal len = 10 / qScale;qScale 就是目前放大值,可以用它調整我們要畫的長度 len;這個解答出自 Heresy's Space。
下面列一下參考書目:
- C++ GUI Programming With Qt 4
- Game Programming using Qt 5 Beginner's Guide: Create amazing games with Qt 5, C++, and Qt Quick






 故事是這樣子的,因為一些個人因素,小弟會常常需要來往東京,幸好現在亞洲廉航選擇多,兩個月左右飛一次還可以承受。
故事是這樣子的,因為一些個人因素,小弟會常常需要來往東京,幸好現在亞洲廉航選擇多,兩個月左右飛一次還可以承受。

 故事是這樣子的,去年十月跟傳說中的幣圈大佬小新大大弄完 Nixie Tube Clock,從小新大大那邊拿到一團剩餘零件,剛好裡面有一批 1206 的白光 LED,想說丟回收前還是可以利用一下,不如就來做個
故事是這樣子的,去年十月跟傳說中的幣圈大佬小新大大弄完 Nixie Tube Clock,從小新大大那邊拿到一團剩餘零件,剛好裡面有一批 1206 的白光 LED,想說丟回收前還是可以利用一下,不如就來做個





